 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine Art Colorization
Line art colorization is the process of adding color to black and white line art using deep learning techniques.
Papers and Code
ChartE$^{3}$: A Comprehensive Benchmark for End-to-End Chart Editing
Jan 29, 2026Charts are a fundamental visualization format for structured data analysis. Enabling end-to-end chart editing according to user intent is of great practical value, yet remains challenging due to the need for both fine-grained control and global structural consistency. Most existing approaches adopt pipeline-based designs, where natural language or code serves as an intermediate representation, limiting their ability to faithfully execute complex edits. We introduce ChartE$^{3}$, an End-to-End Chart Editing benchmark that directly evaluates models without relying on intermediate natural language programs or code-level supervision. ChartE$^{3}$ focuses on two complementary editing dimensions: local editing, which involves fine-grained appearance changes such as font or color adjustments, and global editing, which requires holistic, data-centric transformations including data filtering and trend line addition. ChartE$^{3}$ contains over 1,200 high-quality samples constructed via a well-designed data pipeline with human curation. Each sample is provided as a triplet of a chart image, its underlying code, and a multimodal editing instruction, enabling evaluation from both objective and subjective perspectives. Extensive benchmarking of state-of-the-art multimodal large language models reveals substantial performance gaps, particularly on global editing tasks, highlighting critical limitations in current end-to-end chart editing capabilities.
Region-Wise Correspondence Prediction between Manga Line Art Images
Sep 11, 2025



Understanding region-wise correspondence between manga line art images is a fundamental task in manga processing, enabling downstream applications such as automatic line art colorization and in-between frame generation. However, this task remains largely unexplored, especially in realistic scenarios without pre-existing segmentation or annotations. In this paper, we introduce a novel and practical task: predicting region-wise correspondence between raw manga line art images without any pre-existing labels or masks. To tackle this problem, we divide each line art image into a set of patches and propose a Transformer-based framework that learns patch-level similarities within and across images. We then apply edge-aware clustering and a region matching algorithm to convert patch-level predictions into coherent region-level correspondences. To support training and evaluation, we develop an automatic annotation pipeline and manually refine a subset of the data to construct benchmark datasets. Experiments on multiple datasets demonstrate that our method achieves high patch-level accuracy (e.g., 96.34%) and generates consistent region-level correspondences, highlighting its potential for real-world manga applications.
A Large-scale Dataset for Robust Complex Anime Scene Text Detection
Oct 09, 2025Current text detection datasets primarily target natural or document scenes, where text typically appear in regular font and shapes, monotonous colors, and orderly layouts. The text usually arranged along straight or curved lines. However, these characteristics differ significantly from anime scenes, where text is often diverse in style, irregularly arranged, and easily confused with complex visual elements such as symbols and decorative patterns. Text in anime scene also includes a large number of handwritten and stylized fonts. Motivated by this gap, we introduce AnimeText, a large-scale dataset containing 735K images and 4.2M annotated text blocks. It features hierarchical annotations and hard negative samples tailored for anime scenarios. %Cross-dataset evaluations using state-of-the-art methods demonstrate that models trained on AnimeText achieve superior performance in anime text detection tasks compared to existing datasets. To evaluate the robustness of AnimeText in complex anime scenes, we conducted cross-dataset benchmarking using state-of-the-art text detection methods. Experimental results demonstrate that models trained on AnimeText outperform those trained on existing datasets in anime scene text detection tasks. AnimeText on HuggingFace: https://huggingface.co/datasets/deepghs/AnimeText
Cobra: Efficient Line Art COlorization with BRoAder References
Apr 16, 2025The comic production industry requires reference-based line art colorization with high accuracy, efficiency, contextual consistency, and flexible control. A comic page often involves diverse characters, objects, and backgrounds, which complicates the coloring process. Despite advancements in diffusion models for image generation, their application in line art colorization remains limited, facing challenges related to handling extensive reference images, time-consuming inference, and flexible control. We investigate the necessity of extensive contextual image guidance on the quality of line art colorization. To address these challenges, we introduce Cobra, an efficient and versatile method that supports color hints and utilizes over 200 reference images while maintaining low latency. Central to Cobra is a Causal Sparse DiT architecture, which leverages specially designed positional encodings, causal sparse attention, and Key-Value Cache to effectively manage long-context references and ensure color identity consistency. Results demonstrate that Cobra achieves accurate line art colorization through extensive contextual reference, significantly enhancing inference speed and interactivity, thereby meeting critical industrial demands. We release our codes and models on our project page: https://zhuang2002.github.io/Cobra/.
MangaNinja: Line Art Colorization with Precise Reference Following
Jan 14, 2025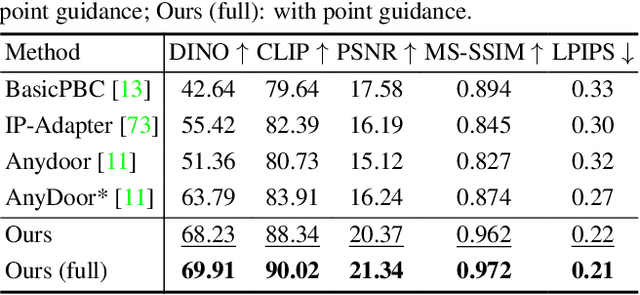
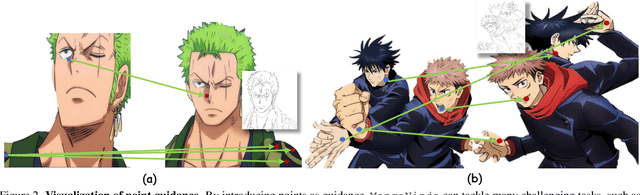
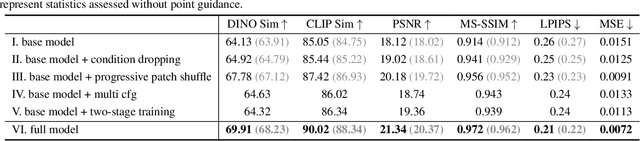
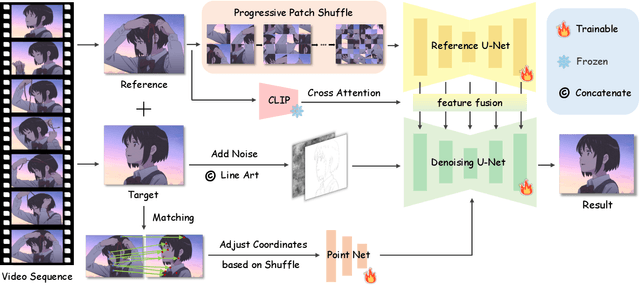
Derived from diffusion models, MangaNinjia specializes in the task of reference-guided line art colorization. We incorporate two thoughtful designs to ensure precise character detail transcription, including a patch shuffling module to facilitate correspondence learning between the reference color image and the target line art, and a point-driven control scheme to enable fine-grained color matching. Experiments on a self-collected benchmark demonstrate the superiority of our model over current solutions in terms of precise colorization. We further showcase the potential of the proposed interactive point control in handling challenging cases, cross-character colorization, multi-reference harmonization, beyond the reach of existing algorithms.
AniDoc: Animation Creation Made Easier
Dec 18, 2024The production of 2D animation follows an industry-standard workflow, encompassing four essential stages: character design, keyframe animation, in-betweening, and coloring. Our research focuses on reducing the labor costs in the above process by harnessing the potential of increasingly powerful generative AI. Using video diffusion models as the foundation, AniDoc emerges as a video line art colorization tool, which automatically converts sketch sequences into colored animations following the reference character specification. Our model exploits correspondence matching as an explicit guidance, yielding strong robustness to the variations (e.g., posture) between the reference character and each line art frame. In addition, our model could even automate the in-betweening process, such that users can easily create a temporally consistent animation by simply providing a character image as well as the start and end sketches. Our code is available at: https://yihao-meng.github.io/AniDoc_demo.
Frequency Enhancement for Image Demosaicking
Mar 20, 2025Recovering high-frequency textures in image demosaicking remains a challenging issue. While existing methods introduced elaborate spatial learning methods, they still exhibit limited performance. To address this issue, a frequency enhancement approach is proposed. Based on the frequency analysis of color filter array (CFA)/demosaicked/ground truth images, we propose Dual-path Frequency Enhancement Network (DFENet), which reconstructs RGB images in a divide-and-conquer manner through fourier-domain frequency selection. In DFENet, two frequency selectors are employed, each selecting a set of frequency components for processing along separate paths. One path focuses on generating missing information through detail refinement in spatial domain, while the other aims at suppressing undesirable frequencies with the guidance of CFA images in frequency domain. Multi-level frequency supervision with a stagewise training strategy is employed to further improve the reconstruction performance. With these designs, the proposed DFENet outperforms other state-of-the-art algorithms on different datasets and demonstrates significant advantages on hard cases. Moreover, to better assess algorithms' ability to reconstruct high-frequency textures, a new dataset, LineSet37, is contributed, which consists of 37 artificially designed and generated images. These images feature complex line patterns and are prone to severe visual artifacts like color moir\'e after demosaicking. Experiments on LineSet37 offer a more targeted evaluation of performance on challenging cases. The code and dataset are available at https://github.com/VelvetReverie/DFENet-demosaicking.
Paint Bucket Colorization Using Anime Character Color Design Sheets
Oct 25, 2024



Line art colorization plays a crucial role in hand-drawn animation production, where digital artists manually colorize segments using a paint bucket tool, guided by RGB values from character color design sheets. This process, often called paint bucket colorization, involves two main tasks: keyframe colorization, where colors are applied according to the character's color design sheet, and consecutive frame colorization, where these colors are replicated across adjacent frames. Current automated colorization methods primarily focus on reference-based and segment-matching approaches. However, reference-based methods often fail to accurately assign specific colors to each region, while matching-based methods are limited to consecutive frame colorization and struggle with issues like significant deformation and occlusion. In this work, we introduce inclusion matching, which allows the network to understand the inclusion relationships between segments, rather than relying solely on direct visual correspondences. By integrating this approach with segment parsing and color warping modules, our inclusion matching pipeline significantly improves performance in both keyframe colorization and consecutive frame colorization. To support our network's training, we have developed a unique dataset named PaintBucket-Character, which includes rendered line arts alongside their colorized versions and shading annotations for various 3D characters. To replicate industry animation data formats, we also created color design sheets for each character, with semantic information for each color and standard pose reference images. Experiments highlight the superiority of our method, demonstrating accurate and consistent colorization across both our proposed benchmarks and hand-drawn animations.
GAC-Net_Geometric and attention-based Network for Depth Completion
Jan 14, 2025



Depth completion is a key task in autonomous driving, aiming to complete sparse LiDAR depth measurements into high-quality dense depth maps through image guidance. However, existing methods usually treat depth maps as an additional channel of color images, or directly perform convolution on sparse data, failing to fully exploit the 3D geometric information in depth maps, especially with limited performance in complex boundaries and sparse areas. To address these issues, this paper proposes a depth completion network combining channel attention mechanism and 3D global feature perception (CGA-Net). The main innovations include: 1) Utilizing PointNet++ to extract global 3D geometric features from sparse depth maps, enhancing the scene perception ability of low-line LiDAR data; 2) Designing a channel-attention-based multimodal feature fusion module to efficiently integrate sparse depth, RGB images, and 3D geometric features; 3) Combining residual learning with CSPN++ to optimize the depth refinement stage, further improving the completion quality in edge areas and complex scenes. Experiments on the KITTI depth completion dataset show that CGA-Net can significantly improve the prediction accuracy of dense depth maps, achieving a new state-of-the-art (SOTA), and demonstrating strong robustness to sparse and complex scenes.
AnyText2: Visual Text Generation and Editing With Customizable Attributes
Nov 22, 2024

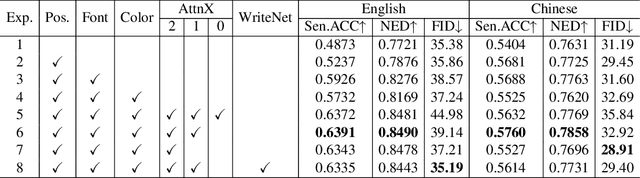

As the text-to-image (T2I) domain progresses, generating text that seamlessly integrates with visual content has garnered significant attention. However, even with accurate text generation, the inability to control font and color can greatly limit certain applications, and this issue remains insufficiently addressed. This paper introduces AnyText2, a novel method that enables precise control over multilingual text attributes in natural scene image generation and editing. Our approach consists of two main components. First, we propose a WriteNet+AttnX architecture that injects text rendering capabilities into a pre-trained T2I model. Compared to its predecessor, AnyText, our new approach not only enhances image realism but also achieves a 19.8% increase in inference speed. Second, we explore techniques for extracting fonts and colors from scene images and develop a Text Embedding Module that encodes these text attributes separately as conditions. As an extension of AnyText, this method allows for customization of attributes for each line of text, leading to improvements of 3.3% and 9.3% in text accuracy for Chinese and English, respectively. Through comprehensive experiments, we demonstrate the state-of-the-art performance of our method. The code and model will be made open-source in https://github.com/tyxsspa/AnyText2.